Research Topics
We use data science and artificial intelligence to solve problems in three different areas: 1) protein sequence and function analysis, 2) computational proteomics, and 3) natural language processing.
實驗室的研究方向為開發計算系統、演算法、以及人工智慧工具以解決生物醫學問題,研究領域包含:1) 蛋白質序列及功能分析,2) 計算蛋白質體學,以及 3) 自然語言處理在生醫文獻與臨床病例資料的應用。
實驗室的研究方向為開發計算系統、演算法、以及人工智慧工具以解決生物醫學問題,研究領域包含:1) 蛋白質序列及功能分析,2) 計算蛋白質體學,以及 3) 自然語言處理在生醫文獻與臨床病例資料的應用。
We want you
Highly motivated students who want to pursue master education or accumulate practical research experiences are encouraged to join us. If you are interested in doing research, or writing programs to solve real problems, or you simply wants to sharpen your programming skills with small projects. We might have something you are looking for. We also welcome students who are interested in our book club.
Undergraduate or graduate students, if you are interested in our research please do not hesitate to write to me.
我們歡迎主動積極、想要攻讀研究所、需要累積作品及成果的學生。如果你對做研究有興趣 (想知道做研究是怎麼一回事)、想嘗試寫程式解決真實世界的問題,或單純想找些小題目磨練自己寫程式的能力,實驗室也可以提供你一些資源協助,我們也歡迎對讀書會主題有興趣的同學,可以加入旁聽。
大學專題生或研究生都歡迎加入我們,請直接寫信與我聊聊。
Undergraduate or graduate students, if you are interested in our research please do not hesitate to write to me.
我們歡迎主動積極、想要攻讀研究所、需要累積作品及成果的學生。如果你對做研究有興趣 (想知道做研究是怎麼一回事)、想嘗試寫程式解決真實世界的問題,或單純想找些小題目磨練自己寫程式的能力,實驗室也可以提供你一些資源協助,我們也歡迎對讀書會主題有興趣的同學,可以加入旁聽。
大學專題生或研究生都歡迎加入我們,請直接寫信與我聊聊。
Computational Proteomics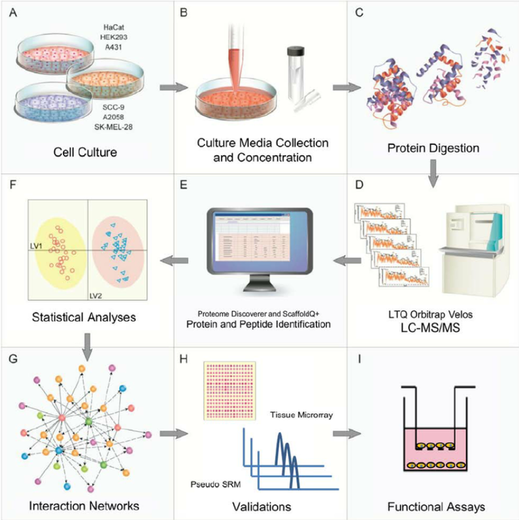
|
Natural Language Processing
Data Science & AI
|
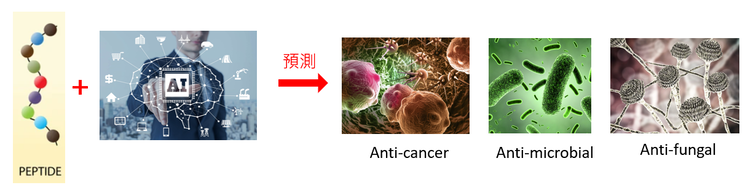
人工智慧及資料科學在醫療用胜肽的開發應用
抗微生物胜肽(Antimicrobial peptides,AMPs)作為抗生素的替代品是未來趨勢,跟抗生素比起來,AMPs可以針對有抗藥性的細菌且並不易累積在人體中,加上用途廣泛,可用在植物以及其他動物上,但目前透過生物實驗篩選方式效率低落,因此我們開發能夠準確預測AMP的機器學習方法,來簡化實驗室的過程,達到降低成本與提高效率的目的,我們的方法包含兩步驟:第一步為適性化特徵工程,第二步為機器學習模型的超參數最佳化。除了成功預測AMP,此方法也成功運用在預測具有溶血毒性的胜肽、抗血管生成的胜肽、抗發炎的胜肽、以及單域抗體的paratope預測等題目,目前進入論文撰寫投稿階段。
計算蛋白質體學
適性化的蛋白質體定量演算法
在常見的蛋白質體定量技術中,同位素標記定量實驗佔有重要角色,因為它具有多重覆特性,能夠在單次實驗中同時定量多個樣本。在同位素標記定量實驗中,最重要的挑戰就是提升定量準確性。同位素標記定量實驗受實驗技術、樣本複雜度、離子物理限制、儀器雜訊等影響,導致圖譜訊號存在誤差,影響到後續生物分析的解讀。
我們設計一套適性化蛋白質體同位素標記定量演算法。因不同蛋白質有不同數目的圖譜數目、胜肽數目、圖譜峰值範圍等,根據我們先前發表的Multi-Q 2論文中,我們發現現今不存在適合所有蛋白質的單一定量演算法。我們設計以一套rule-based混合式定量演算法,以改善使用單一定量演算法造成的限制,進一步提升準確率。
以機器學習技術篩選定量偏差值大的圖譜
在標記化蛋白質體學 (Isobaric labeling proteomics) 定量方法中,圖譜品質決定其定量準確度,然而現今尚不存在結合人工智慧以預測定量偏差值較大的圖譜。我們結合幾套分類能力優秀的機器學習演算法,例如XGBoost, LightGBM, Extra Trees等演算法,針對圖譜進行辨識,將定量偏差值較大的圖譜篩選,保留準確度高的圖譜以作為後續蛋白質體定量所用。
在常見的蛋白質體定量技術中,同位素標記定量實驗佔有重要角色,因為它具有多重覆特性,能夠在單次實驗中同時定量多個樣本。在同位素標記定量實驗中,最重要的挑戰就是提升定量準確性。同位素標記定量實驗受實驗技術、樣本複雜度、離子物理限制、儀器雜訊等影響,導致圖譜訊號存在誤差,影響到後續生物分析的解讀。
我們設計一套適性化蛋白質體同位素標記定量演算法。因不同蛋白質有不同數目的圖譜數目、胜肽數目、圖譜峰值範圍等,根據我們先前發表的Multi-Q 2論文中,我們發現現今不存在適合所有蛋白質的單一定量演算法。我們設計以一套rule-based混合式定量演算法,以改善使用單一定量演算法造成的限制,進一步提升準確率。
以機器學習技術篩選定量偏差值大的圖譜
在標記化蛋白質體學 (Isobaric labeling proteomics) 定量方法中,圖譜品質決定其定量準確度,然而現今尚不存在結合人工智慧以預測定量偏差值較大的圖譜。我們結合幾套分類能力優秀的機器學習演算法,例如XGBoost, LightGBM, Extra Trees等演算法,針對圖譜進行辨識,將定量偏差值較大的圖譜篩選,保留準確度高的圖譜以作為後續蛋白質體定量所用。
